Le Covid 19 met, à nouveau, la mobilité au cœur de nos préoccupations. Le confinement, c'est à dire la limitation plus ou moins généralisée des déplacements est nécessaire pour "étaler la pointe épidémique". Comment en limiter les conséquences économiques ? celles sur les libertés publiques ? Que faire pour faciliter le confinement ? Comment optimiser la dé-mobilité ? Et, si nécessaire, Comment contrôler la mobilité ?
Face aux multiples pénuries de masques, de tests, de médecins... le numérique tel un couteau suisse propose de multiples solutions !
Pour tenter de clarifier le débat, voici un premier tour d'horizon en cinq catégories d'apps qui interagissent avec notre mobilité.
Télé-travail, télé-conférence, télé-éducation...
Whatsapp, Zoom, Google Hangouts pour les plus généralistes facilitent les échanges "à distance", améliorent l'efficacité des télé-conférences classiques.
Teams et Slack prolongent cette panoplie avec des fonctions de collaboration et de travail d'équipe. L'intégration avec les annuaires d'entreprises et avec de nombreux autres outils de bureautique et de productivité, conduit à un véritable "environnement de travail en équipe". Le confinement apporte l'élément déclencheur pour mettre en oeuvre ces nouveaux usages. Reste à savoir si ces nouvelles habitudes auront ou pas un impact durable.
Télé-diagnostic
En période de pandémie, le télé-diagnostic prend tout son intérêt. Il peut s'agir de "téléconsultations" simples extensions de la catégorie précédente à la médecine dont le nombre semble avoir explosé depuis le début de l'épidémie avec 100 000 télé-consultations par jour actuellement.
Il peut aussi s'agir de questionnaire d’auto-diagnostic comme le CoronaCheck suisse ou de "chat bot" comme le "Covid bot" de Clevy une start-up spécialisée dans les interfaces conversationnelles.
Enfin, Sanofi a communiqué sur un partenariat avec Luminostic qui permettrait d'analyser des échantillons à partir d'un dispositif qui s'adapte sur le smartphone. Sanofi vise une disponibilité fin 2020.
Identification des "cas contacts"
Identifier les "cas contacts" consiste à identifier toutes les personnes ayant été en contact avec un malade pour créer un risque de contamination dans la période pendant laquelle ce malade était contagieux mais non isolé. Dans le cas du SARS-Cov-V2, c'est complexe puisque la période peut être longue. C'est ce problème que plusieurs applications tentent de résoudre. On peut citer les initiatives suivantes, même si, pour le moment aucune application n'est opérationnelle en France.
L'initiative conjointe Apple/Google, visant à faciliter l'interopérabilité en BlueTooth entre une application de traçage sur I-Phone et la même application sur Android et réciproquement.
Dans un second temps, Apple et Google envisagent de coopérer sur une fonction de traçage plus complète qui faciliterait l'interopérabilité entre différentes applications de traçage installées sur différents téléphones. De telles solutions ont été mises en oeuvre, avec un certain succès apparemment en Asie. Le principe général est décrit dans cette infographie :

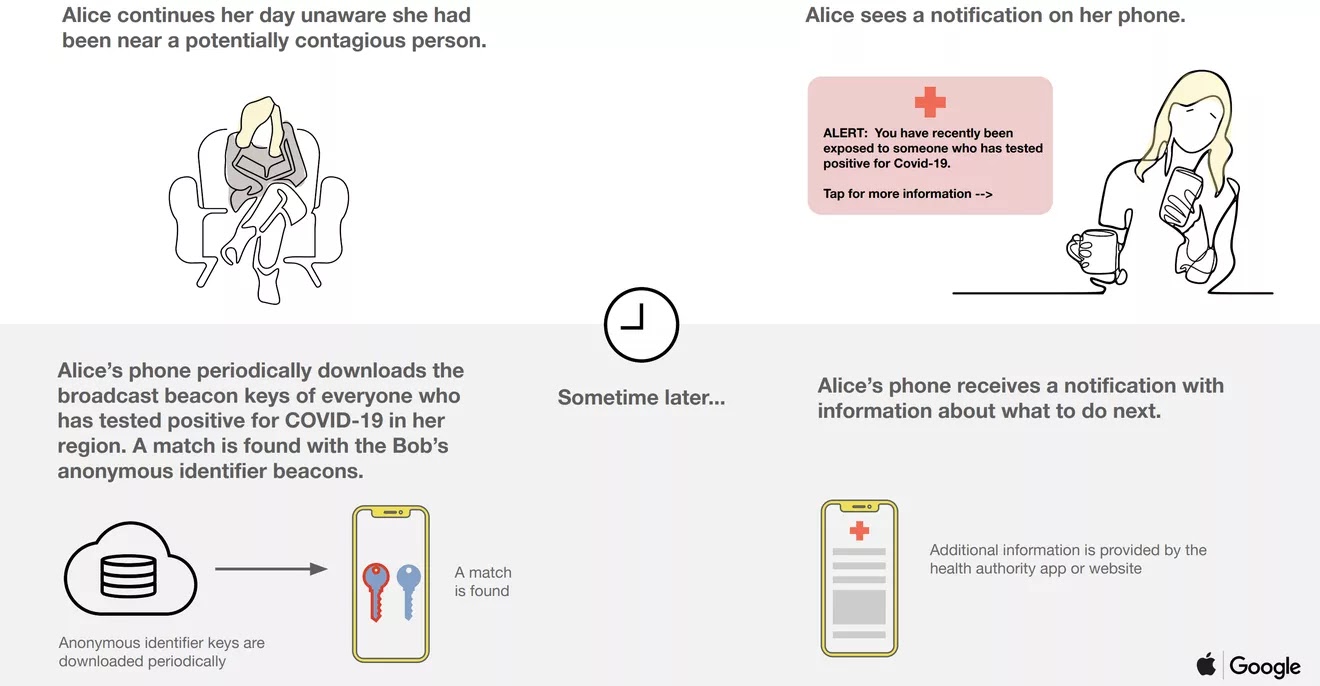
En Europe, l'INRIA avec un protocole intitulé Robert, co-développé avec le Fraunhofer tente de s'intégrer dans une initiative européenne PEPP-PT. Les équipes suisses de l'EPFL et de l'ETH Zurich travaillent sur un protocole DP-3T qui pourrait aussi déboucher sur une solution pan-européenne.
Les débats, qui ralentissent le choix d'une solution, portent sur l'équilibre entre efficacité du traçage et protection de la vie privée.
- On peut imaginer que le système n'utilise que le bluetooth à l'exclusion de toute technologie de localisation. Que les informations ne soient stockées que de façon décentralisées c'est à dire sur les portables des personnes ayant été en contact. Qu'elles soient protégées par des dispositifs cryptologiques visant à rendre très difficile l'identification des contacts. Et enfin que toutes les actions : déclaration par le malade, sollicitation de l'alerte par les cas contacts et bien entendu décision de la suite à donner par le cas contact, soient du seul ressort des propriétaires des téléphones.
- A l'inverse, on peut proposer de compléter les informations de proximité des bluetooth par des dispositifs de géo-localisation, centraliser toutes les informations, permettre aux agences de santé de déclarer les malades et forcer les cas contact à adopter un comportement ad-hoc.
Certains se réjouiront de voir l'Europe prendre le temps d'un débat éthique et politique avant de trancher cette question au niveau national ou européen, d'autres ne manqueront pas de s'en agacer en déplorant le retard que nous prenons sur les pays déjà équipés (Mise à jour : l'Australie vient de publier de COVIDSafe).
Contrôle des déplacements
Une différence essentielle entre les réflexions européennes et les réalisations chinoises (telles que présentées dans la vidéo ci-dessous), est que les dispositifs chinois vont au delà du simple traçage des cas contacts pour faire du smartphone un véritable système de contrôle des déplacements.
Il semble que les applications évaluent les risques liés au propriétaire du téléphone sur la base de ses déplacements, de ces contacts, mais peut-être aussi d'autres facteurs. Ce risque, restitué par une couleur rouge, orange, verte permet l'accès à certains lieux ou pas...
Ce genre de système qui semble totalement inadapté dans une société respectueuse des droits des personnes...
En revanche, des applications mobiles pourraient être largement utilisées pour contingenter les accès à certaines zones pour limiter l'affluence aux heures de pointes et faciliter le respect d'une distance suffisante entre les gens. Il s'agirait, simplement, d'étendre les fonctions de réservations bien acceptées pour les restaurants, les coiffeurs, les musées, les médecins à d'autres lieux. A quand une réservation pour aller au parc ? au marché ou au supermarché ? dans les transports ?
